Table of Contents
To think before one speaks is to consider a set of possible responses and choose the one that best conveys one’s intent. This is a task that most humans do intuitively and quickly, but is not something that is easily incorporated into modern AI systems. Compared to the intricacy of large language model (LLM) architectures, the methods used to sample responses from an LLM, given a prompt, are simple and heuristic driven.
Given a prompt by the user, the LLM first decides which word out of all words in the dictionary should come first in its response. This decision is made by choosing the word with the highest estimated likelihood, given the model’s training and the context provided in the form of a prompt. Note that at this point, the LLM has no information about the rest of its response to weigh in on its word choice.
Crucially, this initial word choice may end up being a mistake in the long run because the final likelihood of the generated response may have been higher if a different initial word had been chosen. This problem compounds with each word choice as sentences and paragraphs are constructed by the model. Unfortunately, it is impossible for LLMs to exhaustively search for the best response to a query. The reason for this is practical: to guarantee the best possible response to a prompt would require scoring $L^V$ responses, where $L$ is the length of the response and $V$ is the size of the vocabulary. For human language, $V$ is on the order of $10^4$ and response lengths can be hundreds of words long. Clearly, this computational problem is intractable. The practical outcome is that it is extremely unlikely, if not almost guaranteed, that the response from the LLM is not the best possible response it could have given.
It is interesting that LLMs work as well as they do despite the relative simplicity of their sequence generation. This may be one reason why LLMs require such a large amount of training data relative to humans to generate meaningful language. Fortunately, LLMs contain additional information that can be used to generate responses more efficiently. The LLM’s gradient, like the slope of a line, points in the direction of higher scoring response. This means that it is not necessary to move blindly through the response search space, like the greedy heuristic. Rather, the gradient can be used to sample better responses with much higher probability than otherwise. It is not known if using gradient information from a set of initial heuristic samples meaningfully improves LLM responses. This article attempts to address that question to the extent that a lone Apple iMac is capable. To do this, two questions need to be addressed:
- To what extent are higher likelihood language samples associated with more nuanced, complex responses?
- Can the gradient of the LLM’s log likelihood, $\nabla \log{\hat{p}(x \mid \theta, c)}$, otherwise known as the score function, be used to generate a set of higher likelihood samples?
Language Models
As far as one believes that humans convey their reasoning and knowledge through language, and as far as one believes that human language can be approximated by an arbitrarily complex statistical model, then we can propose that there is a probability distribution over all possible sequences of words $x = (x_1,\dots,x_n)$ that humans are likely to generate.
\[p(x)\]Of course, the “true” nature of human language $p(x)$ is unknown and therefore requires mathematical approximation. Enter LLMs. The billions of weights inside an LLM encode correlations between words, sentences, and paragraphs. However, these weights represent only a static set of variables that are not capable of generating a sequence on their own. A method is required to “decode” the weights inside the model into a generated sequence given contextualizing information $c$, such as a prompt provided to the LLM from a human. In other words, a method is required to roll metaphorical dice to generate a sequence $x$ with probability $p$, given context $c$.
\[x \mid c \sim p(x)\]The challenge LLMs tackle is twofold: estimating $p(x)$ and then sampling (generating) a reply to a prompt $c$ that maximizes $p(x \mid c)$.
Estimating p(x) with an LLM
LLMs represent a transformational improvement in our ability to estimate the likelihood of human language. An LLM is a function $f$ parameterised by $\theta$, $f_\theta$, that consumes context $c$ and estimates the probability distribution over the vocabulary at each position $i$ within the generated sequence. For this reason, an LLM can be viewed as an approximating density for $p(x \mid c) \approx \hat{p}(x \mid \theta,c)$. The best response $x_{\texttt{best}}$ from the LLM is then the point of highest conditional density $\hat{p}(x \mid c,\theta)$, which directly means that $x_{\texttt{best}}$ must maximize $f_\theta$.
\[p(x \mid c) \approx \hat{p}(x \mid \theta,c)\] \[\hat{p}(x \mid \theta,c) = f_\theta(x)\] \[x_{\text{best}} = \underset{x}{\operatorname{argmax}} f_\theta(x)\]The problem encountered by modern LLMs is that building a very good likelihood estimator was only half the problem. The other half is to sample the best response given context to the model. This is equivalent to finding the maximum of the likelihood function $f_{\theta}$. However, this requires checking all $L^V$ responses. As discussed above, this is an intractable problem.
Peak Finding vs. Peak Mapping
Imagine you have decided to drop yourself at a random location in the middle of Himalayas. Your goal is to find the highest peak, Everest, by only walking upwards. Crucially, once any peak in the mountain range is reached, you can no longer climb upwards so the task must complete. There are 3,411 named peaks in the Himalayas, of which only 1 is Mt. Everest. Clearly it is quite improbable to find Mt. Everest using this algorithm. This algorithm is known as gradient ascent, and it is related to how LLMs are trained.
 | Figure 1. Zoomed in area around Mt. Everest in the Himalayas.|
| Figure 1. Zoomed in area around Mt. Everest in the Himalayas.|
Now imagine that you once again find yourself in the middle of the Himalayas. Rather than only climbing until a peak is reached, you continuously move around in a way that respects these rules:
- As you move uphill, you lose momentum and tend to make smaller moves
- As you move downhill, you gain momentum and start making larger moves
- In flat regions, your momentum doesn’t change and you make large moves until you either start climbing again (1) or descending again (2)
- You only stop moving after a pre-determined number of steps.
If this is done with an element of randomness, you will provably end up visiting peaks in the Himalayas proportionally to how high they are – virtually ensuring that you will eventually find the peak of Mt. Everest.
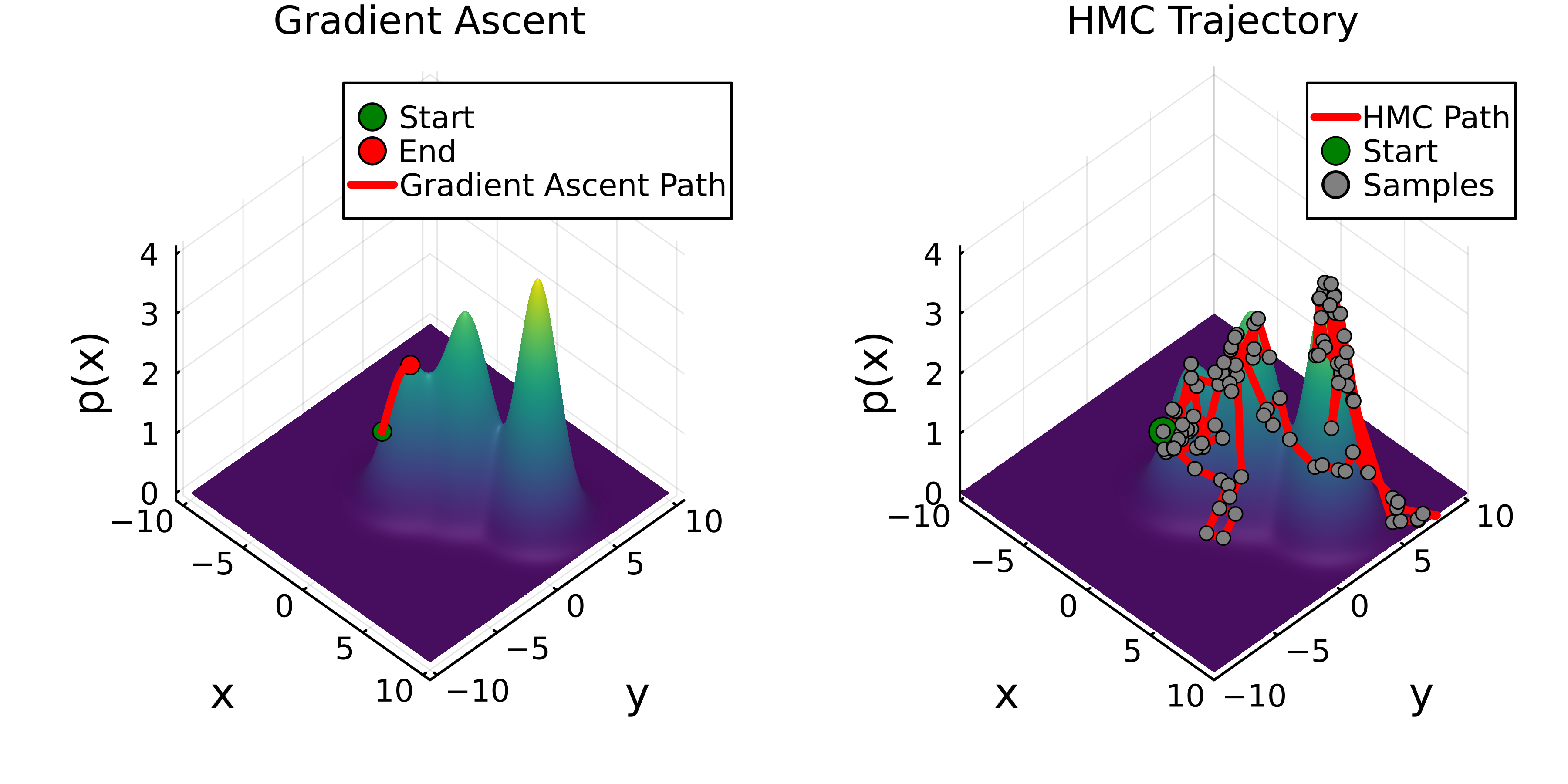
Figure 2. Gradient based generated sequence optimization. Left: Given an initial prediction from the model, the gradient of the LLM $\nabla f_\theta$ points the next prediction in a direction that is guaranteed to give a higher likelihood response, however these methods get trapped in local minima. Right: Gradient-based monte carlo samplers such as HMC use the gradient of the LLM $\nabla f_\theta$ to draw samples from $f_\theta$ proportionally to how likely the samples are from the model.
Mathematically, these algorithms can be expressed the following way and be used to generate the plots in Fig. 2:
Gradient Ascent
$x_{i+1} \leftarrow x_i + η ∇f_θ(x_i)$
Gradient MCMC Samplers (HMC)
$p_{i+1/2} \leftarrow p_i + (η/2) ∇f_θ(x_i)$
$x_{i+1} \leftarrow x_i + η p_{i+1/2}$
$p_{i+1} \leftarrow p_{i+1/2} + (η/2) ∇f_θ(x_{i+1})$
Thinking like an LLM
Given these limitations, current LLM performance may be no where near its true level of knowledge or approximation of human language. It is possible that improvements to LLMs will come from a team of mathematicians and computer scientists in a few lines of math, rather than relying on exponentially more data.
Our brains effortlessly sample language with essentially no error, especially on common knowledge subjects. The frequent and nonsensical “hallucinations” of an LLM are essentially a poor estimate for $\max{f_{LLM}}$ that a human brain would never make.
As sampling algorithms for generative AI improves, we will get a better picture of the true level of knowledge store in modern LLMs. I strongly suspect that better exploration of the sequence space via improved markov-chain monte carlo methods or similar will result in improved AI performance despite the data ceiling.
Notes
LLMs do not estimate the true likelihood of a sequence but rather the pseudolikelihood.
You generate an initial proposal response, but then reevaluate the response. You pass the initial response through the LLM which gives a probability/pseudolikelihood of the response. The calculation of that probability/pseudolikelihood is differentiable.
However my sampling choices at each position in the sequence are discrete, meaning they cannot be connected to this gradient. This is resolvable, potentially, by using a continuous relaxation calculation of the samples.
Initial → Continuous Relaxation → Gradient Updates → Final Argmax tokens (Gumbel-Softmax) (using f_θ) (discrete tokens)
From yang song
When sampling with Langevin dynamics, our initial sample is highly likely in low density regions when data reside in a high dimensional space. Therefore, having an inaccurate score-based model will derail Langevin dynamics from the very beginning of the procedure, preventing it from generating high quality samples that are representative of the data.
^ We solve this maybe by doing a greedy beam search then optimize